Windpower Competency Center
The 4th Industrial revolution extends the vertical integration of Industry 3.0 – Digital Revolution – adding a new dimension of horizontal integration – between companies – which is impossible without Digital Transformation that focuses on maximizing usage of the digital technologies across the whole Value Chain. The cornerstone of Digital Transformation was proposed by SAP and named the Digital Core.
In the sea of the innumerable ways to the Digital Transformation, Digital Core can become both an iceberg and an island that allows an enterprise management apparatus to recharge and continue its journey through the Industry 4.0. Also, Keel has a set of skills to become a keel for your enterprise management vessel in this smartified sea.
The 12-year experience in the Wind Power Industry equipped Keel with the vision of the problem, and this is a hole in the Data Engineering and Data Science that increases with the increase of the data volume making companies DRIP (Data Rich – Information Poor).
Data Engineering and Data Science with Keel
In Europe in 2017 the number of new wind turbines installed offshore hit 560 units with the average distance to shore 41 km, which is an indicator of the high service expenses related to transportation of spare parts, personnel and tools. These expenses sometimes are doubled when wrong data lead to the purchase of expensive equipment which cannot be put in place demanding an additional round of purchase and delivery. Negative experiences like this can be eliminated with the investment in Data Projects that are Cost Avoidance reified.
Extraction of benefits from data is carried out through Data Pipeline, which is an array of elements connected in such a way that the output of one element serves as an input for the next element in the processing chain.
The Data Pipeline is similar to DNA – it defines how data is gathered, filtered, stored, shared, processed et al. Over time a flaw in Data Pipeline creates tumor-like chunks of data that only consume resources with zero return, demanding brownfield restructuration, and Keel has successfully completed several projects of this type. It doesn’t come as a surprise that Keel is much more experienced in data preparation than data analysis, because it’s estimated that only 10% of Data Analysis Project time is taken by the analysis itself.
Greenfield and brownfield projects of setting Data Pipeline are very similar and their stages are described below.
Data Engineering
Data Engineering can be summed up as the creation of the system with rules that guide the further data usage.
Ingestion
This stage is more relevant for the greenfield project because during this stage data is obtained from a source (or multiple sources), moved to the location when it will be processed. Meanwhile, the brownfield projects are executed in the determined place for a known set of data given by a customer.
Cleansing
Noise removal
Outliers detection
Missing values handling
Validation
Identification of false values in a dataset using causal relations.
Transformation
To process the data, it has to have a unified form (structure) across the whole dataset. Transformation for a greenfield project is a structurization of the raw data, while the brownfield projects usually require retransformation, which is an alignment with the current and future need done by the old structure conversion or enhancement.
Shaping
This is the combination of filtering, sorting, combining and parameters reduction.
Data Preparation
To increase the efficiency of the analysis the data is prepared, so it can easily be used by analytics without concern about technical aspects of the data.
Refining
Roughly speaking, this is a convention of the data structure from easy-to-use ( human-friendly) to easy-to-implement (machine-friendly), which is a structure optimized for a particular usage, e.g. a usage by a Convolutional Neural Network.
Orchestration
This stage is all about organizing the synchronization across different sources and users so that everyone has a real-time update of the data.
Virtualization
Adding of a virtual layer between an end-user and data to allow the user to retrieve relevant data from different sources as if it stored in one repository.
Blending
Data comes in a broad variety of formats and number of sources, which causes complications for an analyst. For that reason data has to be merged into a unified multidimensional dataset which can be analyzed.
Shaping
This is the combination of filtering, sorting, combining and parameters reduction.
Data Analytics
Data analysis is the extraction of benefits from the data generated by IIoT with the help of data science tools.
People don’t want data; they want answers – David Hand.
(Emeritus Professor of Mathematics, Imperial College)
Building
The first step of the analysis is the development of models for supervised and unsupervised machine learning. The type of the model (regression, clustering, et al.) is picked for each purpose individually..
Evaluation
The training dataset is given to the machine to build a predictive model, which is evaluated by the accuracy of predictions for the validation set.
Tuning and Testing
After evaluation, the model is put to the test to reveal the possible issues like overfitting. If problems were discovered, the model is tuned and tested again until its accuracy is acceptable.
Deployment
The models are deployed in the real IIoT environment to give real-time feedback on the situation allowing utilization of the data by getting deep, sometimes hidden, insight.
Maintenance
During the usage models are continuously monitored and improved when new problems of data appear.
Nevertheless, working with a pipeline for a customer, Keel is working on the development of classification models helpful in the data cleansing and structurization processes. We expect at least 70-80% of work to be passed to the machine, though the precise numbers will be known when the models are developed.
On the other hand, the Big Data Analytics allows an efficient resource allocation, for example in the maintenance, by analyzing the lifecycle of assets in real-time with probabilistic and statistical models, it’s possible to be one step ahead of the current situation.
According to Deloitte Predictive Maintenance Position Paper, Predictive maintenance increases equipment uptime by 10 to 20% while reducing overall maintenance costs by 5 to 10% and maintenance planning time by 20 to 50%.
RDS-PP as a structural foundation for Data Analysis
RDS-PP is a convenient technical language designed in the intersection of more than 27 standards that supervise the information transition along the lifetime axis of a power plant, drawing a smooth management line through the dots of design, control, procurement, service and even decommissioning.
The Machinery Directive for The European Union demands compliance with the ISO/TS 81346-10, which in its turn requires power plants to use reference designations. VGB PowerTech has developed such a system, naming it Reference Designation System for Power Plants (VGB-B 101 and VGB-B 102). Additionally to the RDS-PP VGB has provided a guideline and part 32 of this guideline, (VGB-S-823-32), Wind Power Plants, has been successfully implemented by Keel for over 4000 turbines around the globe.
It is possible to draw a parallel between RDS-PP and chess where every piece has a name according to its functionality making impossible to confuse the bishop with the knight. When all players in the Wind Power Energy sector play according to the RDS, the information can be easily transferred across the industry enabling us to see the industry-size picture and adding a bonus feature of passing assets and eliminating problems of merging the databases and enterprises.
From the technical point of view, RDS-PP is a tool for naming system elements – power plants in particular – according to their projection on the different aspects, the most important of which is the functional aspect. The naming of components according to their Functional Aspect creates a hierarchy independent from the system where it’s used, so that the structure can be transferred between platforms and databases. Adaptation of RDS gives a large number of benefits, some of which are listed below.
- New employee training time is reduced and simplified, especially when the employee has been exposed to the industry.
- Cross-Platform usage.
- Design Reuse.
- System awareness and Object recognition.
- Easy BOM creation, simplification of procurement and 3rd party interaction in general.
However, the usage of RDS-PP creates some challenges as well, particularly the necessity to filter out information for the different users. For instance, the construction of a wind turbine doesn’t go along RDS tree but instead leaps from one point in the structure to another, and the lowest serviceable level drastically differs for an offshore and onshore wind turbine due to the transportation costs. At the moment Keel is working on the perfection of the RDS adaptation for the different users, developing in parallel a Neural Network for the RDS creation for existing objects.
Classification
The system-of-systems approach of the RDS is too global to be scaled down to the material level without overcomplicating the overall assets management process. However, there are other systems of naming product with the leader – eCl@ss – which is the system for describing product and services. The eCl@ss is ISO/IEC standards compliant methodology for the classifying and describing of products and services and is sometimes referred to as the language of Industry 4.0.
The core advantage of using eCl@ss lays on the horizontal integration axis and can be summed up as a way to join dots into the Smart Revolution enterprise-to-enterprise collaboration. In essence, eCl@ss is a pass into the blockchain based e-commerce, where spare parts or any other product or service can be ordered automatically with minimal human input, thereby minimizing human error.
Also, the eCl@ss database is continually expanding to aggregate the missing classes, and the latest release 10.1, contains:
- 42220 commodity classes,
- 18867 different properties,
- 17022 values.
The number of members has grown from 12 at the start to 150 today (2018).
The eCl@ss system is based on a four-layer hierarchy of application classes and their structural elements, which vary between Basic and Advanced dictionary versions.
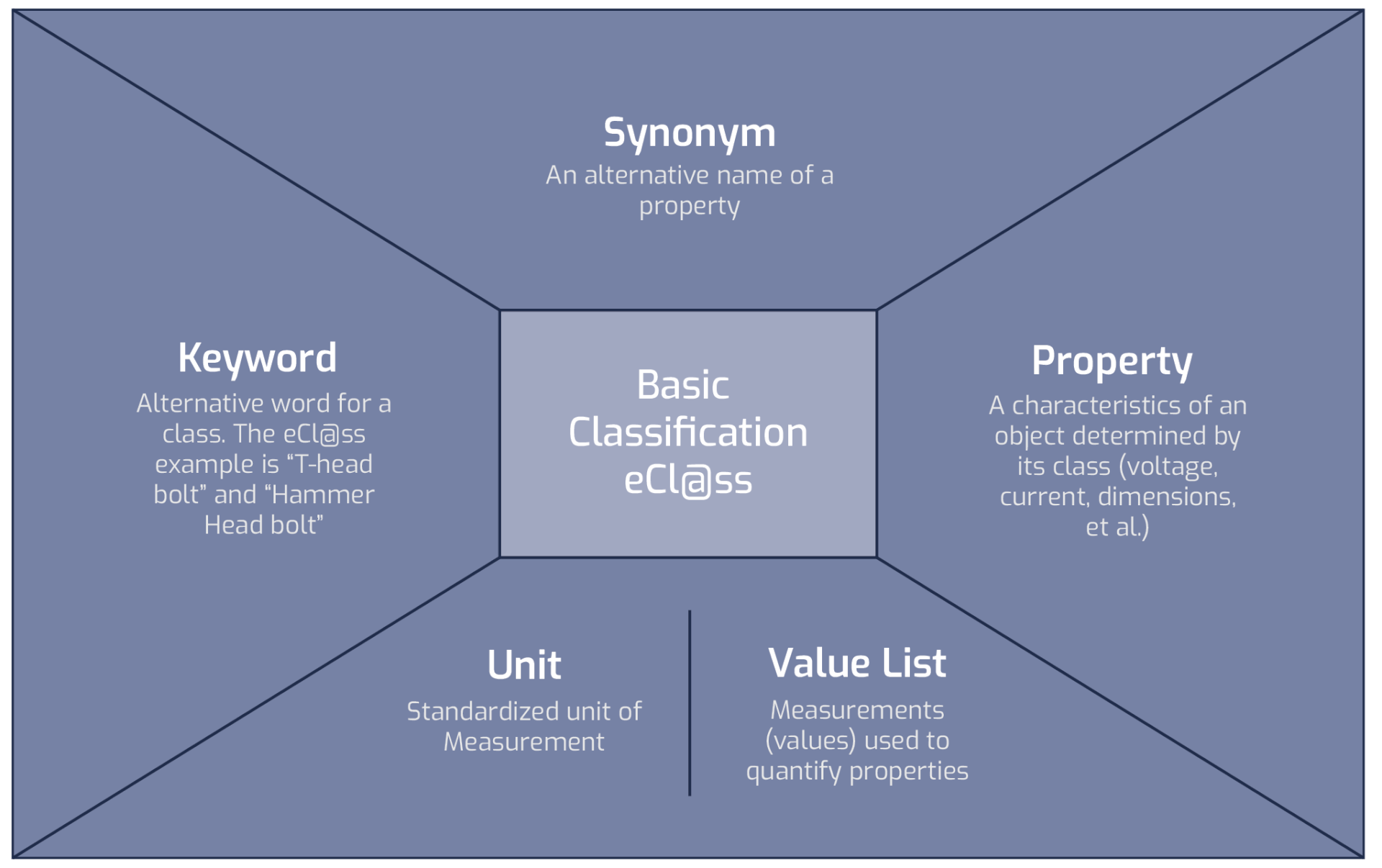
Usage of eCl@ss provides tools for the creation of machine-readable structure (XML) files for products; thus the design process can be computer-aided to a higher degree.
Anchor Blockchain
It’s impossible to say nothing about Blockchain when speaking about Windpower 4.0. According to the IBM paper, 91% of responders’ banks reported investing in blockchain solutions; and it’s estimated that by 2020 a whopping 66% of banks are expected to have a commercial blockchain solution at scale.
At the present time, Keel is having negotiations regarding the blockchain application, which will help our customers to stay in the Industry 4.0 ocean.
Never-ending improvement
A decade ago Keel had gathered a few specialists to form an enterprise cell which by sharing and expanding evolved into the company we are today. We have formed our own approach in Asset Data Management and, being attracted to it, we grew as a company nurturing a new generation of specialists that works with us today.
We are trying to be error-free while sailing through the depths on innovation driven by our own enthusiasm and the winds of industry.
Download our Windpower 4.0 Brochure.


We are ready to help!
Request consultation, ask a question or share your feedback. Just get in touch!



